Apache Kafka
Introduction
This document contains my notes on Apache Kafka, which I studied from Udemy Course "Apache Kafka Series - Learn Apache Kafka for Beginners v3" by Stephane Maarek
Why Apache Kafka
- Decoupling of data streams and systems
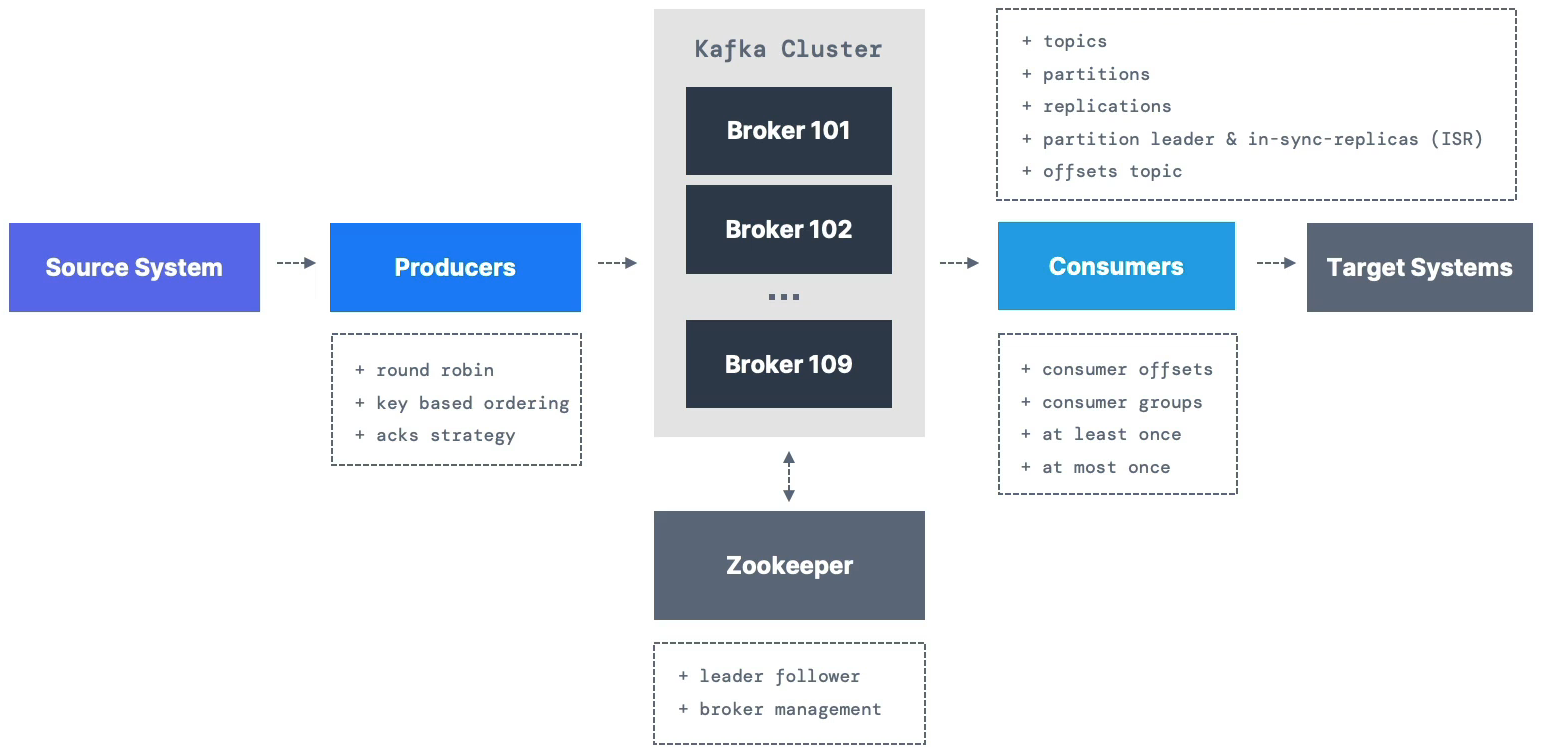
- N Source Systems ---> Kafka ---> N Target Systems
- Distributed, resilient architecture, fault tolerant
- Horizontal scalability:
- Can scale to 100s of brokes
- Can scale to millions of messages per second
- High performance (latency of less than 10ms) - real life
Apache Kafka Use Cases
- Messaging System
- Activity Tracking
- Gather metrics from many different locations
- Application Logs gathering
- Stream processing (with the Kafka Streams API for example)
- De-coupling of system dependencies
- Integration with Spark, Flink, Storm, Hadoop and many other Big Data Technologies
- Micro-services pub/sub
Real use cases examples:
- Netflix - uses Kafka to apply recommendations in real-time while you're watching TV shows
- Uber - uses Kafka to gather user, taxi and trip data in real-time to compute and forecast demand, and compute surge pricing in real-time
- LinkedIn - uses Kafka to prevent spam, collect user interactions to make better connection recommendations in real time.
[!NOTE] Kafka is only used as a transportation mechanism!
Course Material Download
Kafka Theory
Topics
- Topics: a particular streams of data
- Like a table in database (without all the constrains)
- One can have as many topics as one want
- A topic is identified by its name
- Topics support any kind of message format (e.g. json, txt, binary etc.)
- The sequence of message is called a data stream
- One can not query topics, instead, use Kafka Producers to send data and Kafka Consumers to read the data
- Kafka topics are immutable
- Data is kept only for a limited time (default is one week, but configurable)
Partitions and Offsets
- Topics are split in partitions (e.g. 100 partitions)
- Messages within each partition are ordered
- Each message within a partition gets an incremental ID, called offset
- Kafka topics are immutable: once data is written to a partition, it can not be changed
- Offset only have a meaning for a specific partition
- E.g. offset 3 in partition 0 doesn't represent the same data as offset 3 in partition 1
- Offsets are not re-used even if previous message have been deleted
- Order is guaranteed only within a partition (not across partitions)
- Data is assigned randomly to a partition unless a key is provided
- One can have as many partitions per topic as one want
Producers
- Producers write date to topics (which are made of partitions)
- Producers know in advance to which partition to write to (and which Kafka broker has it)
- In case of Kafka failure, Producers will automatically recover
Producer's Message Key
- Producers can choose to send a key with the messsage (string, number, binary, etc.)
- if
key=null, data is sent round robin (partition 0, then 1, then 2..) - if
key!=null, then all messages for that key will always go to the same partition (hashing) - A key are typically sent if you need message ordering for a specific field (ex: truck_id)
Kafka Messages Anatomy
- Key-binary
- can be null
- Value-binary
- can be null
- Compression Type
- none
- gzip
- snappy
- lz4
- zstd
- Headers (optional)
- key/value
- key/value
- Partition+Offset
- Timestamp (system or user set)
Kafka Message Serializer
- Kafka only accepts bytes as an input from producers and sends bytes out as an output to consumers
- Message Serialization means transforming objects/data into bytes
- Serializers are used on the value and the key
- Kafka comes with Common Serializers
- String (incl. JSON)
- Int, Float
- Avro
- Protobuf
Kafka Message Key Hashing
- A Kafka partitioner is a code logic that takes a record and determines to which partition to send it into
- Key Hashing is the process of determining the mapping of a key to a partition
- In the defualt Kafka partitioner, the keys are hashed using the marmur2 algorithm with the formula below:
targetPartition = Math.abs(Utils.marmur2(keyBytes)) % (numPartitions - 1)
Consumers
- Consumers read data from a topic (identified by name) - pull model
- Consumers automatically know which broker to read from
- In case of broker failures, consumers know how to recover
- Data is read in order from low to high offset within each partitions
Consumer Deserializers
- Deserialize indicates how to transform bytes into objects/data
- Deserializers are used on the value and the key of the message
- Kafka Common Deserializers
- String (incl. JSON)
- Int, Float
- Avro
- Protobuf
[!NOTE] The serialization/deserialization type must not change during a topic lifecycle
Consumer Groups
- All the consumers in an application read data as a consumer groups
- To create distinct consumer groups, use consumer property
group.id - Each consumer within a group reads from exclusive partitions
- If one have more consumers than partitions, some consumers will be inactive
- Multiple Consumers on one topic
- In Apache Kafka it is acceptable to have multiple consumer groups on the same topic
- E.g. 1 consumer service for location, 1 consumer service for notification in track example
Consumer Offsets
- Kafka stores the offsets at which a consumer group has been reading
- The offsets committed are in Kafka topics named
__consumer_offsets - When a consumer in a group has processed data reveived from Kafka, it should be periodically committing the offsets (the Kafka broker will write to
__consumer_offsets, not to the group itself)
Delivery semantics for consumers
- By default, Java Consumers will automatically commit offsets (at least once)
- There are 3 delivery semantics if you choose to commit manually:
- At least once (usually preferred)
- Offsets are committed after the message is processed
- If the processing goes wrong, the message will be read again
- If message is read again, it can result in duplicate processing of messages. Make sure your processing is idempotent (i.e. processing again the messages will not impact your systems)
- At most once
- Offsets are committed as soon as messages are received
- If the processing goes wrong, some messages will be lost (i.e. they will not be read again)
- Exactly once
- for Kafka -> Kafka workflows: use the Transactional API (easy with Kafka Streams API)
- for Kafka -> External System workflow: use an idempotent consumer
- At least once (usually preferred)
Kafka Brokers
- A Kafka Cluster is composed of multiple brokers (servers)
- Each broker is identified with its ID (integer)
- Each broker contains certain topic partitions
- After connecting to any broker (called a bootstrap broker), you will be connected to the entire cluster (Kafka clients have smart mechanics for that)
- A good number to get started is 3 brokers, but some big clusters have over 100 brokers
Kafka vs Topics
- Example of Topic-A with 3 partitions and Topic-B with 2 partitions, where data is distributed
- Broker 101
- Topic-A Partition 0
- Topic-B Partition 1
- Broker 102
- Topic-A Partition 2
- Topic-B Partition 0
- Broker 103
- Topic-A Partition 1
- Broker 101
Kafka Broker Discovery
- Every Kafka broker is also called a bootstrap server
- That means that you only need to connect to one broker, and the Kafka clients will know how to be connected to the entire cluster (smart client)
- Each broker knows about all brokers, topics and partitions (metadata)
Topic Replication
Topic Replication Factor
- Topics should have a replication factor > 1 (usually between 2 and 3)
- This way if a broker is down, another broker can serve the data
- Example: Topic-A with 2 partitions and replication factor of 2 (e.g. if we lose broker 102, brokers 101 and 103 can still server the data)
- Broker 101
- Topic-A Partition 0
- Broker 102
- Topic-A Partition 1
- Topic-A Partition 0 (Replication)
- Broker 103
- Topic-A Partition 1 (Replication)
- Broker 101
Concept of Leader for a Partition
- At any time only ONE broker can be a leader for a given partition
- Producers can only send data to the broker that is leader of a partition
- The other brokers will replicate the data and therefore, each partition has one leader and multiple ISR (in-sync replica)
- Example above with Leader for Partitions
- Broker 101
- Topic-A Partition 0 (Leader)
- Broker 102
- Topic-A Partition 1 (Leader)
- Topic-A Partition 0 (Replication)(ISR)
- Broker 103
- Topic-A Partition 1 (Replication)(ISR)
- Broker 101
Default Producer & Consumer behaviour with leaders
- Kafka Producers can only write to the leader broker for a partition
- Kafka Consumers by default will read from the leader broker for a partition
Kafka Consumers Replica Fetching (Kafka v2.4+)
- Since Kafka 2.4, it is possible to configure consumers to read from the closest replica
- This may help to improve latency, and also decrease network costs if using the cloud
Kafka Topic Durability
- For a topic replication factor of 3, topic data durability can withstand 2 broker loss
- As a rule, for a replication factor of
N, you can permanently lose up toN-1broker and still recover your data
Producer Acknowledgements (acks)
- Producers can choose to receive acknowledgment of data writes:
acks = 0: Producer won't wait for acknowledgment (possible data loss)acks = 1: Producer will wait for leader acknowledgment (limited data loss)acks = all: Leader + replicas acknowledgment (no data loss)
Zookeeper
- Zookeeper manages brokers (keeps a list of them)
- Zookeeper helps in performing leader election for partition if broker goes down
- Zookeeper sends notifications to Kafka brokers in case of changes (e.g. new topic, broker dies, broker comes up, delete topic, etc.)
- Kafka up to version v2.x can't work without Zookeeper
- Kafka 3.x can work without Zookeeper (KIP-500) - using Kafka Raft (KRaft) instead
- Kafka 4.x will not have Zookeeper anymore
- Zookeeper by design operates with an odd number of servers (1, 3, 5, 7)
- Zookeeper has a leader(writes) the rest of the servers are followers (reads)
- (Zookeeper does NOT store consumer offsets with Kafka > v0.10)
- Example:
- Zookeeper Server 1 (Follower)
- Kafka Broker 1
- Kafka Broker 2
- Zookeeper Server 2 (Leader)
- Kafka Broker 3
- Kafka Broker 4
- Zookeeper Server 3 (Follower)
- Kafka Broker 5
- Zookeeper Server 1 (Follower)
Should you use Zookeeper?
- With Kafka Brokers?
- Yes, until Kafka 4.0 is out while waiting for Kafka without Zookeeper to be production-ready
- With Kafka Clients?
- Over time, the Kafka Clients and CLI have been migrated to leverage the brokers as a connection endpoint instead of Zookeeper
- Since Kafka v0.10, consumers store offset in Kafka Broker and Zookeeper and they must not connect to Zookeeper as it is deprecated
- Since Kafka v2.2,
kafka-topics.shCLI command references Kafka Brokers and not Zookeeper for topic management (creation, deletion, etc.) and the Zookeeper CLI argument is deprecated - All the APIs and commands that were previously leveraging Zookeeper are migrated to use Kafka instead, so that when clusters are migrated to be without Zookeeper, the change is invisible to clients
- Zookeeper is also less secure than Kafka, and therefore Zookeeper ports should only be opened to allow traffic from Kafka Brokers, and not Kafka Clients
[!NOTE] Never use Zookeeper as a configuration in your Kafka Client, and other program that connect to Kafka.
Kafka KRaft
-
In 2020, the Apache Kafka project started to work to remove the Zookeeper dependency from it (KIP-500)
-
Zookeeper shows scaling issues when Kafka cluster have > 100,000 partitions
-
By removing Zookeeper, Apache Kafka can
- Scale to millions of partitions, and becomes easier to maintain and set-up
- Improve stability, makes it easier to monitor, support and administer
- Single security model for the whole system (not Kafka or Zookeeper separately)
- Single process to start with Kafka
- Faster controller shutdown and recovery time
-
Kafka 3.x now implements the Raft protocol (KRaft) in order to replace Zookeeper
- Production ready since Kafka 3.3.1 (KIP-833)
- Kafka 4.0 will be released only with KRaft (no Zookeeper)
Kafka KRaft Architecture
- With Zookeeper
Zookeeper Server 1 +------ Kafka Broker 1
Zookeeper Server 2 (Leader) -----+------ Kafka Broker 2
Zookeeper Server 3 +------ Kafka Broker 3
- With Quorum Controller
Kafka Broker 1 <---> Kafka Broker 2 (L) <---> Kafka Broker 3
L - Quorum Leader
[!NOTE] KRaft Performance Improvements with controller shutdown time and recovery time after uncontrolled shutdown. (see here )
Starting Kafka
Start Kafka using Docker
See How to Start Kafka using Docker?
CLI
Kafka CLI
- Kafka CLI comes with Kafka binaries
- Use
--bootstrap-serveroption for e.g.kafka-topicsbut NOT--zookeeper(deprecated)- e.g.
kafka-topics --bootstrap-server localhost:9092
- e.g.
Kafka Topics CLI
- Kafka Topic Management
- Create Kafka Topics
- List Kafka Topics
- Describe Kafka Topics
- Increase Partitions in a Kafka Topics
- Delete a Kafka Topic
# Examples
kafka-topics.sh --bootstrap-server localhost:9092 --list
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --create
kafka-topics.sh --bootstrap-server localhost:9092 --topic second_topic --create --partitions 3
kafka-topics.sh --bootstrap-server localhost:9092 --topic third_topic --create --partitions 3 --replication-factor 2
# Create a topic (working)
kafka-topics.sh --bootstrap-server localhost:9092 --topic third_topic --create --partitions 3 --replication-factor 1
# List topics
kafka-topics.sh --bootstrap-server localhost:9092 --list
# Describe a topic
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --describe
# Delete a topic
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --delete
# (only works if delete.topic.enable=true)
Kafka Console Producer CLI
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --create --partitions 1
# producing
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first_topic
> Hello World
>My name is Conduktor
>I love Kafka
>^C (<- Ctrl + C is used to exit the producer)
# producing with properties
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first_topic --producer-property acks=all
> some message that is acked
> just for fun
> fun learning!
# producing to a non existing topic
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic new_topic
> hello world!
# our new topic only has 1 partition
kafka-topics.sh --bootstrap-server localhost:9092 --list
kafka-topics.sh --bootstrap-server localhost:9092 --topic new_topic --describe
# edit config/server.properties or config/kraft/server.properties
# num.partitions=3
# produce against a non existing topic again
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic new_topic_2
hello again!
# this time our topic has 3 partitions
kafka-topics.sh --bootstrap-server localhost:9092 --list
kafka-topics.sh --bootstrap-server localhost:9092 --topic new_topic_2 --describe
# overall, please create topics with the appropriate number of partitions before producing to them!
# produce with keys
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first_topic --property parse.key=true --property key.separator=:
>example key:example value
>name:Stephane
What is Next?
- Kafka for Beginners: Kafka basics operations, producers and consumers
- Kafka Connect API: Import/Export data to/from Kafka
- Kafka Streams API: Process and Transform data within Kafka
- ksqlDB: Write Kafka Streams applications using SQL
- Confluent Components: REST Proxy and Schema Registry
- Kafka Security: Setup Kafka security in a Cluster and Integrate your applications with Kafka Security
- Kafka Monitoring and Operations: use Prometheus and Grafana to monitor Kafka, learn operations
- Kafka Cluster Setup and Administration: Get a deep understanding of how Kafka and Zookeeper works, how to setup Kafka and various administration tasks
- Confluent Certifications